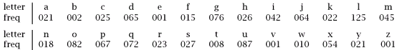| (a) |
What is a monoalphabetic substitution
cipher?
|
[2] | |||||||||
| (b) |
How does a polyalphabetic substitution
cipher differ from a monoalphabetic one?
|
[1] | |||||||||
| (c) |
What is it that makes a polyalphabetic
substitution cipher more secure than a monoalphabetic cipher?
|
[2] | |||||||||
| (d) |
Explain the difference between a block
cipher and a stream cipher. Which is the more secure?
|
[2] | |||||||||
| (e) |
Explain how to decrypt a monoalphabetic
substitution cipher.
compare with the (known or estimated) frequency distribution of plain text, and match uptoobtain a firstguessat themapping(1 mark); finding the complete mapping may take some trial and error, especially for infrequent letters, as the two distributions will probably not match precisely (1 mark); use can also be made of known or probable plaintexts (1 mark).
|
[4] | |||||||||
| (f) |
Decrypt the following extract from a block of ciphertext. nxlotpqyrgmld pd ksq It is English text, encrypted using a monoalphabetic cipher. The complete ciphertext had the frequency distribution, in letters per thousand,
For reference, the frequency distribution
of ordinary English text, also in letters per thousand, is Sorting the
letters of the alphabet according to their frequency in ordinary English
yields the sequence
(1 mark). Assuming the
distributions match precisely, an l in the ciphertext decrypts to
an e in plaintext, a u to a t, and so on:
(1 mark).
It is also reasonable
to assume that the h in the plaintext should be an s (again, these
two letters are adjacent in frequency), yielding the final plaintext
(1 mark for the correct plaintext). (Award some marks if they manage to crack the code by any other means; for example, by guessing the plaintext somehow!) |
[4] |